mysql monitor 명령어
접속 부터
1) 윈도우키+R -> cmd
2) cd C:\Bitnami\wampstack-5.5.26-0\mysql\bin (비트나미로 부터 bin 폴더까지)
mysql -hlocalhost -uroot -p 엔터, 패스워드 넣으라 하면 DB 비번 입력
db 존재 확인
3) show databases; 명령으로 현재 존재하는 데이터 베이스 확인
db생성
4) CREATE DATABASE dbName CHARACTER SET utf8 COLLATE utf8_general_ci;
db삭제
5) 잘못 만들었으면 삭제 - DROP DATABASE dbName;
db사용
6) USE dbName;
--------------------------------------------------------------------------------
테이블 생성
1) CREATE TABLE `topic` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(100) NOT NULL,
`description` text NOT NULL,
`author` varchar(30) NOT NULL,
`created` datetime NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
※ `topic`, `id` 등 에 쓰인 `은 물결표시 밑의 그레이브엑센트 이다.
일반 홑따움표와 다르다.
※ int(11) 11의 의미는 출력될때 11자리까지만 출력된다는 뜻
만들어진 테이블 확인
2) show tables;
3) 테이블에 행 추가하면서 데이터 삽입 - INSERT INTO `topic`
(`id`, `title`, `description`, `author`, `created`)
VALUES(
'title_aaaa',
'desctiption_aaaa',
'author_aaaa',
'2015-06-30 19:05:00'
);
id는 하나 하나 추가 될때만다 1, 2, 3 이런식으로 증가되서 자동 기입 된다.
auto_increment 속성 때문
테이블의 상세 모양세 보기
4) DESC tableName;
--------------------------------------------------------------------------------
내용 변경 - 추가
1) INSERT INTO tableName
(colName1, colName2, colName3) VALUES (`값1`, `값2`, `값3` );
내용 변경 - 변경
2) UPDATE tableName SET colName1 = '값', colName2 = '값'
WHERE colName3= '값';
내용 변경 - 삭제
3) DELETE FROM tableName WHERE colName = '값'
내용 선택
4) SELECT colName1, colName2 FROM tableName;
조건
SELECT colName1, colName2 FROM tableName
WHERE colName3= 값 AND(OR) colName4= 값;
정렬
SELECT colName1, colName2 FROM tableName ORDER BY colName3 DESC(ASC);
Auto Increment 초기화, 모든 테이블 내용이 삭제 되야 초기화 됨
5) ALTER TABLE tableName AUTO_INCREMENT = 1;
--------------------------------------------------------------------------------
테이블 변경 - 컬럼 추가
1)ALTER TABLE tablename ADD name varchar(10);
ex) alter table [테이블명] add [컬럼명] varchar(100) not null default '0';
ALTER TABLE tablename ADD newColName varchar(10) AFTER existColName;
/* 컬럼 삭제 */
ALTER TABLE tablename DROP colname;
/* 컬럼명 변경 및 타입 변경 */
ALTER TABLE tablename CHANGE colname newcolname INT NOT NULL AUTO_INCREMENT;
CHANGE는 컬럼 속성뿐아니라 이름도 바꿔준다.
/* 컬럼 타입 수정 */
alter table [테이블명] modify [컬럼명] varchar(14);
/* 테이블명 수정 */
ALTER TABLE tablename RENAME newtablename;
/* 테이블 삭제 */
drop table [테이블명];
--------------------------------------------------------------------------------
2015년 6월 28일 일요일
php
php
php로 작성된 부분은 web server에 의해 php interpretor에 위임되어 행해지는 부분이고
java script로 작성된 부분은 web browser에 의해 행해지는 부분이다.
web browser 페이지의 소스를 보면 js는 작성한 그대로 보이지만
php코드 부분은 결과만을 확인할 수 있다. 이유가 바로 위에서 언급한 특징 때문이다.
<?php
php코드
?>
※<?php .. 에서 ?와 p 사이에 띄어쓰기 하면 안됨
<script>
java script 코드
</script>
---------------------------------------------------------------------
- echo
echo "Hello world"; //문자의 경우" "로 감싸줘야 한다.
echo 10000;
echo "10000"+"10000"; //20000 출력
echo "H"+"W";//0 출력
echo "10" . "10";//1010 출력 // . 은 두 문자열 연결
---------------------------------------------------------------------
- $변수명
: 앞에 $를 붙인다.
---------------------------------------------------------------------
- 배열
$list = array("1","2","3"); // php , ※ var list = new Array("1","2","3"); // java script
- 배열의 크기
$size = count($list); // php , ※ var size = list.length; // js
---------------------------------------------------------------------
- 함수
function FuncPHP($input)
{
return $input + 1;
}
- 함수 호출
FuncPHP(3);
---------------------------------------------------------------------
-디렉토리(경로) 관리
getcwd(); // 현재 디렉토리 구함
chdir("../"); // 경로 변경, ("../" 은 부모 경로 = 한 계층 위 의미 )
chdir("폴더명"); // 해당 경로로 이동
$dir = "./"; // = current directory
$files1 = scandir($dir);//경로내 파일들 순차 정렬
$files2 = scandir($dir, 1);//경로내 파일들 역순 정렬
만들기
mkdir("1/2/3/4", 0700, true);
//1이라는 폴더 밑에 2 밑에 3 밑에 4라는 폴더가 없으면 만든다. 있으면 warning
//0700: 권한 설정, 오너 그룹 아더, 자세한건 추후 기입
//true: 1/2/3 까지의 경로가 없다면 1,2,3을 만들어 준다는 설정 설정
---------------------------------------------------------------------
-파일명 보안
basename = 이하 b 로 표시
b("/etc/sudoers.d", ".d"); // -> "sudoers"
b("/etc/sudoers.d"); // -> "sudoers.d"
b("/etc/pass"); // -> "pass"
b("/etc/"); // -> "etc"
b("."); // -> "."
b("/"); // -> ""
//이렇게 파일명만을 추려내는 기능 이스케이핑 같은 목적으로 사용
---------------------------------------------------------------------
-ini 설정 runtime 변경
ini_set("display_error", "1");
//
---------------------------------------------------------------------
-이미지 파일 전송 받아 출력하기
form 태그로 전송 받은 경우 form 속 input 의 name="이름" 을 이용해서
$_POST["이름"] 으로 사용할 수 있지 않을까? 하는 생각은 버리자
파일의 경우 $FILES 라는 약속된 변수에 저장되어 있다.
"이름"은 폼 태그 하위 인풋 태그에서 사용한 name="이름" 의 그 이름이다.
$FILES["이름"] 으로 배열화 되어있는 파일의 정보에 접근할 수 있다.
$FILES["이름"]["name"] //-> 파일 이름. 확장자
$FILES["이름"]["type"] //-> image 인지 text 인지 / 형식?(png , plain 등 )
$FILES["이름"]["tmp_name"] //->템프 경로, 파일을 목표 경로로 옮기기 전 잠시있는 곳
$FILES["이름"]["error"] //-> 전송중? 에러 사항?
$FILES["이름"]["size"] //-> 파일 용량
$uploadDir = '경로\\';// 이 경로는 서버의 물리적 경로
//경로 까지만 담고있고 끝에 역슬래쉬가 두개 있는게 특징. 윈도우에서만 그렇다
$uploadFile = $uploadDir.basename($_FILES["이름"]["name"]);
//경로에 파일명을 붙여주는 작업, .을 이용해 텍스트+텍스트 해준다.
//basename은 여기서는 이스케이핑 역할, 정확한 파일명만 추리기 위해
if( move_uploaded_file($_FILES["이름"]["tmp_name"], $uploadFile)){
echo " 파일 유효 업로드 성공";
}
else {
print "파일 업로드 공격의 가능성이 있음";
}
//임시파일로 존재하는 파일을 $uploadFile 로서 해당 위치와 파일명으로 이동
<img src="file/<?=$_FILES['userFile']['name']?>" />
//이미지를 출력, 이곳 src="URL" 임, php파일이 있는 경로에 이미지 파일이 있음
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
php로 작성된 부분은 web server에 의해 php interpretor에 위임되어 행해지는 부분이고
java script로 작성된 부분은 web browser에 의해 행해지는 부분이다.
web browser 페이지의 소스를 보면 js는 작성한 그대로 보이지만
php코드 부분은 결과만을 확인할 수 있다. 이유가 바로 위에서 언급한 특징 때문이다.
<?php
php코드
?>
※<?php .. 에서 ?와 p 사이에 띄어쓰기 하면 안됨
<script>
java script 코드
</script>
---------------------------------------------------------------------
- echo
echo "Hello world"; //문자의 경우" "로 감싸줘야 한다.
echo 10000;
echo "10000"+"10000"; //20000 출력
echo "H"+"W";//0 출력
echo "10" . "10";//1010 출력 // . 은 두 문자열 연결
---------------------------------------------------------------------
- $변수명
: 앞에 $를 붙인다.
---------------------------------------------------------------------
- 배열
$list = array("1","2","3"); // php , ※ var list = new Array("1","2","3"); // java script
- 배열의 크기
$size = count($list); // php , ※ var size = list.length; // js
---------------------------------------------------------------------
- 함수
function FuncPHP($input)
{
return $input + 1;
}
- 함수 호출
FuncPHP(3);
---------------------------------------------------------------------
-디렉토리(경로) 관리
getcwd(); // 현재 디렉토리 구함
chdir("../"); // 경로 변경, ("../" 은 부모 경로 = 한 계층 위 의미 )
chdir("폴더명"); // 해당 경로로 이동
$dir = "./"; // = current directory
$files1 = scandir($dir);//경로내 파일들 순차 정렬
$files2 = scandir($dir, 1);//경로내 파일들 역순 정렬
만들기
mkdir("1/2/3/4", 0700, true);
//1이라는 폴더 밑에 2 밑에 3 밑에 4라는 폴더가 없으면 만든다. 있으면 warning
//0700: 권한 설정, 오너 그룹 아더, 자세한건 추후 기입
//true: 1/2/3 까지의 경로가 없다면 1,2,3을 만들어 준다는 설정 설정
---------------------------------------------------------------------
-파일명 보안
basename = 이하 b 로 표시
b("/etc/sudoers.d", ".d"); // -> "sudoers"
b("/etc/sudoers.d"); // -> "sudoers.d"
b("/etc/pass"); // -> "pass"
b("/etc/"); // -> "etc"
b("."); // -> "."
b("/"); // -> ""
//이렇게 파일명만을 추려내는 기능 이스케이핑 같은 목적으로 사용
---------------------------------------------------------------------
-ini 설정 runtime 변경
ini_set("display_error", "1");
//
---------------------------------------------------------------------
-이미지 파일 전송 받아 출력하기
form 태그로 전송 받은 경우 form 속 input 의 name="이름" 을 이용해서
$_POST["이름"] 으로 사용할 수 있지 않을까? 하는 생각은 버리자
파일의 경우 $FILES 라는 약속된 변수에 저장되어 있다.
"이름"은 폼 태그 하위 인풋 태그에서 사용한 name="이름" 의 그 이름이다.
$FILES["이름"] 으로 배열화 되어있는 파일의 정보에 접근할 수 있다.
$FILES["이름"]["name"] //-> 파일 이름. 확장자
$FILES["이름"]["type"] //-> image 인지 text 인지 / 형식?(png , plain 등 )
$FILES["이름"]["tmp_name"] //->템프 경로, 파일을 목표 경로로 옮기기 전 잠시있는 곳
$FILES["이름"]["error"] //-> 전송중? 에러 사항?
$FILES["이름"]["size"] //-> 파일 용량
$uploadDir = '경로\\';// 이 경로는 서버의 물리적 경로
//경로 까지만 담고있고 끝에 역슬래쉬가 두개 있는게 특징. 윈도우에서만 그렇다
$uploadFile = $uploadDir.basename($_FILES["이름"]["name"]);
//경로에 파일명을 붙여주는 작업, .을 이용해 텍스트+텍스트 해준다.
//basename은 여기서는 이스케이핑 역할, 정확한 파일명만 추리기 위해
if( move_uploaded_file($_FILES["이름"]["tmp_name"], $uploadFile)){
echo " 파일 유효 업로드 성공";
}
else {
print "파일 업로드 공격의 가능성이 있음";
}
//임시파일로 존재하는 파일을 $uploadFile 로서 해당 위치와 파일명으로 이동
<img src="file/<?=$_FILES['userFile']['name']?>" />
//이미지를 출력, 이곳 src="URL" 임, php파일이 있는 경로에 이미지 파일이 있음
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
---------------------------------------------------------------------
2015년 6월 25일 목요일
css
참고 사이트
<head>
<meta charset="utf-8">
<style>
--여기가 CSS 부분, style 테그 안쪽 부분
</style>
</head>
----------------------------------------------------------------
- 반영될 항목 지정
html tag 이름 직접 입력 하는 경우
h1, h2, input {
color: red;
font-size: 10px
text-decoration:underline;
}
//head 태그 하위의 h1에만 적용
header h1{
border: 1px;
border-style: solid;
border-color: red;// transparent는 투명
}
//class="btn_start" 인 것에 적용
.btn_start{
width: 250px;
height: 35px;
font-size: 17px;
}
//id="btn_start" 인 것에 적용
#btn_start{
text-decoration: underline;
}
----------------------------------------------------------------
- css 파일 분리
<head>
<meta charset="utf-8">
<link rel="stylesheet" type="text/csss" href="http://gsyan.iptime.org:8080/style.css">
--link로 이 문서 외부에 존재하는 style.css문서의 내용을 이곳에 대체 한다는 뜻
-- 중복의 제거, 수정작업 효율성 증대 기대
<head>
<meta charset="utf-8">
<style>
--여기가 CSS 부분, style 테그 안쪽 부분
</style>
</head>
----------------------------------------------------------------
- 반영될 항목 지정
html tag 이름 직접 입력 하는 경우
h1, h2, input {
color: red;
font-size: 10px
text-decoration:underline;
}
//head 태그 하위의 h1에만 적용
header h1{
border: 1px;
border-style: solid;
border-color: red;// transparent는 투명
}
//class="btn_start" 인 것에 적용
.btn_start{
width: 250px;
height: 35px;
font-size: 17px;
}
//id="btn_start" 인 것에 적용
#btn_start{
text-decoration: underline;
}
----------------------------------------------------------------
- css 파일 분리
<head>
<meta charset="utf-8">
<link rel="stylesheet" type="text/csss" href="http://gsyan.iptime.org:8080/style.css">
--link로 이 문서 외부에 존재하는 style.css문서의 내용을 이곳에 대체 한다는 뜻
-- 중복의 제거, 수정작업 효율성 증대 기대
html
<!DOCTYPE html>
이 html 문서가 어떤 표준안에 따라 작성되었는가를 표현
--------------------------------------------------------------
<head>
이 안에 들어가는 내용들
</head>
<meta charset = "utf-8" /> // 한글이 안깨지게 해줌
<title> 웹 창의 타이틀 </title>
--------------------------------------------------------------
<body>
이 안에 들어가는 내용들
</body>
tag <a>
<a href = "url"> 링크 </a> // 현재 창에서 이동
<a href = "url" target="_self"> 링크 </a> // 현재 창에서 이동
<a href = "url" target="_blank"> 링크 </a> // 새창에서 열기
tag <ol>, <ul>
<ol>
<li>html</li>
<li>css</li>
<li>java</li>
<li>순서필요함 ordered list</li>
</ol>
<ul>
<li>지은호</li>
<li>지은동</li>
<li>순서필요없음 unordered list</li>
</ul>
Tag Reference
--------------------------------------------------------------
Debug
참고사이트
1) 크롬 우측 상단의 메뉴버튼 / 도구 더 보기 / 자바 스크립트 콘솔 -> 오류 메세지 확인
2) apache2 / logs / error.log 를 atom에서 열어서 제일 밑에 있는 최신 에러항목 확인
--------------------------------------------------------------
Escape( 이스케이핑)
& -> & (ampersand, &, 앤드 기호)
< -> < ( less than )
> -> > ( greater then )
" -> " ( quatation mark )
&apos -> ' ( apostrophe )
--------------------------------------------------------------
공백문자
 
이 html 문서가 어떤 표준안에 따라 작성되었는가를 표현
--------------------------------------------------------------
<head>
이 안에 들어가는 내용들
</head>
<meta charset = "utf-8" /> // 한글이 안깨지게 해줌
<title> 웹 창의 타이틀 </title>
--------------------------------------------------------------
<body>
이 안에 들어가는 내용들
</body>
<a href = "url"> 링크 </a> // 현재 창에서 이동
<a href = "url" target="_self"> 링크 </a> // 현재 창에서 이동
<a href = "url" target="_blank"> 링크 </a> // 새창에서 열기
tag <ol>, <ul>
<ol>
<li>html</li>
<li>css</li>
<li>java</li>
<li>순서필요함 ordered list</li>
</ol>
<ul>
<li>지은호</li>
<li>지은동</li>
<li>순서필요없음 unordered list</li>
</ul>
Tag Reference
--------------------------------------------------------------
Debug
참고사이트
1) 크롬 우측 상단의 메뉴버튼 / 도구 더 보기 / 자바 스크립트 콘솔 -> 오류 메세지 확인
2) apache2 / logs / error.log 를 atom에서 열어서 제일 밑에 있는 최신 에러항목 확인
--------------------------------------------------------------
Escape( 이스케이핑)
& -> & (ampersand, &, 앤드 기호)
< -> < ( less than )
> -> > ( greater then )
" -> " ( quatation mark )
&apos -> ' ( apostrophe )
--------------------------------------------------------------
공백문자
 
2015년 6월 19일 금요일
git
=================================================
- 설치
http://www.git-scm.com/ 에서 다운로드
기본 설치
=================================================
- GUI 환경에서 다루기 위해 SourchTree 설치
http://www.sourcetreeapp.com 에서 다운로드 설치
=================================================
- git ignore 적용 시 윈도우에서 .파일명 안먹힐때
- Create the text file gitignore.txt
- Open it in a text editor and add your rules, then save and close
- Hold SHIFT, right click the folder you're in, then select Open command window here
- Then rename the file in the command line, with
ren gitignore.txt .gitignore
=================================================
- 저장소 클론(다 가져오기)
git clone https://github.com/gsyan/Space119N.git
(실행된 폴더에 프로젝트명 폴더 생기고 그 안에 모든 파일들 복사됨)
-버전 다운
git checkout HEAD~1 : 한단계씩
git checkout HEAD~10
-다시 최신버전
git checkout master
-특정커밋으로 가기
sha : 8b3f06590783f7a570560d13b8d5022945c41767
git checkout 8b3f06590783f7a570560d13b8d5022945c41767
2015년 6월 18일 목요일
operator= 의 자기대입 방어
#include <memory>
class CBitMap
{
public:
CBitMap() { printf("BitMap()\n"); }
CBitMap(const CBitMap& b)
{ printf("CBitMap(const CBitMap& b)\n"); }
};
class CCharacter
{
private:
CBitMap* m_pb;
public:
CCharacter()
{
printf("CCharacter()\n");
m_pb = new CBitMap();
}
CCharacter(const CBitMap& b)
{
printf("CCharacter(const BitMap& bp)\n");
m_pb = new CBitMap(b);
memcpy(m_pb, &b, sizeof(b));
}
void Swap(CCharacter& c)
{
CBitMap* pbOrg = m_pb;
m_pb = new CBitMap(*c.m_pb);
c.m_pb = pbOrg;
}
CCharacter& operator=(const CCharacter& c)
{
printf("operator=\n");
//자기대입에 대한 방어
//1안) 비교
/*if( this == &c )//자기 자신이라면
{ return *this; }
delete m_pb;//아무 조건 없이 지움
m_pb = new CBitMap(*c.m_pb);//만약 여기서 예외가 발생한다면? m_pb는 망함;
return *this;*/
///////////////////////////////////////////////////////////////////////////////////
//2안) 원래 값을 따로 저장해 둔 후 삭제, new의 fail에 대처하는 자세
/*CBitMap* pbOrg = m_pb;
CBitMap* temp = new CBitMap(*c.m_pb);
if(temp == NULL)
{ return *this; }
m_pb = temp;
delete pbOrg;*/
///////////////////////////////////////////////////////////////////////////////////
//3안) 복사 후 맞 바꾸기(copy and swap)
/*CCharacter temp(*c.m_pb);
Swap(temp);
delete temp.m_pb;
return *this;*/
}
};
int _tmain(int argc, _TCHAR* argv[])
{
CBitMap b;
CCharacter c1(b);
CCharacter c2;
c2 = c1;
return 0;
}
class CBitMap
{
public:
CBitMap() { printf("BitMap()\n"); }
CBitMap(const CBitMap& b)
{ printf("CBitMap(const CBitMap& b)\n"); }
};
class CCharacter
{
private:
CBitMap* m_pb;
public:
CCharacter()
{
printf("CCharacter()\n");
m_pb = new CBitMap();
}
CCharacter(const CBitMap& b)
{
printf("CCharacter(const BitMap& bp)\n");
m_pb = new CBitMap(b);
memcpy(m_pb, &b, sizeof(b));
}
void Swap(CCharacter& c)
{
CBitMap* pbOrg = m_pb;
m_pb = new CBitMap(*c.m_pb);
c.m_pb = pbOrg;
}
CCharacter& operator=(const CCharacter& c)
{
printf("operator=\n");
//자기대입에 대한 방어
//1안) 비교
/*if( this == &c )//자기 자신이라면
{ return *this; }
delete m_pb;//아무 조건 없이 지움
m_pb = new CBitMap(*c.m_pb);//만약 여기서 예외가 발생한다면? m_pb는 망함;
return *this;*/
///////////////////////////////////////////////////////////////////////////////////
//2안) 원래 값을 따로 저장해 둔 후 삭제, new의 fail에 대처하는 자세
/*CBitMap* pbOrg = m_pb;
CBitMap* temp = new CBitMap(*c.m_pb);
if(temp == NULL)
{ return *this; }
m_pb = temp;
delete pbOrg;*/
///////////////////////////////////////////////////////////////////////////////////
//3안) 복사 후 맞 바꾸기(copy and swap)
/*CCharacter temp(*c.m_pb);
Swap(temp);
delete temp.m_pb;
return *this;*/
}
};
int _tmain(int argc, _TCHAR* argv[])
{
CBitMap b;
CCharacter c1(b);
CCharacter c2;
c2 = c1;
return 0;
}
2015년 6월 17일 수요일
상속 객체 복사
class CCharacter
{
protected:
char* m_name;
public:
CCharacter():m_name(0) {printf("CCharacter()\n");}
CCharacter(char* name)
{
m_name = new char[strlen(name)+1];
strcpy(m_name, name);
}
CCharacter(const CCharacter& c)
{
printf("CCharacter& c \n");
m_name = new char[strlen(c.m_name)+1];
strcpy(m_name, c.m_name);
}
~CCharacter() { delete[] m_name; }
CCharacter& operator=(const CCharacter& c)
{
printf("operator=\n");
if(this == &c) { return *this; }
if(m_name != NULL) { delete[] m_name; }
m_name = new char[strlen(c.m_name)+1];
strcpy(m_name, c.m_name);
return *this;
}
char* GetName() { return m_name; }
};
class CHighElf : public CCharacter
{
private:
int m_level;
public:
CHighElf():m_level(0) {}
CHighElf(char* name, int lv=0):CCharacter(name), m_level(lv) {}
CHighElf(const CHighElf& h):/*CCharacter(h),*/ m_level(h.m_level)
{
//괄호 위에 있는 CCharacter(h), 이 핵심
//이 부분이 괄호 위로 올라감으로 해서 CCharacter 기본 생성자가 호출되지 않고
//바로 CCharacter 복사 생성자가 호출.
//CCharacter::CCharacter(h); // 이렇게 하면 기본 생성자 호출
//m_level = h.m_level;
}
~CHighElf() {}
CHighElf& operator=(const CHighElf& h)
{
//CCharacter::operator=(h);//부모 클래스의 대입연산자도 호출해 줘야한다.
m_level = h.m_level;
return *this;
}
const int GetLevel() { return m_level; }
void Print() { printf("name: %s level: %d\n",m_name, m_level); }
};
int _tmain(int argc, _TCHAR* argv[])
{
//상속없는 객체의 복사, 대입
CCharacter* c1 = new CCharacter("c1");
printf("c1 name: %s\n", c1->GetName());
CCharacter* c2 = new CCharacter(*c1);
printf("c2 name: %s\n", c2->GetName());
CCharacter* c3 = new CCharacter();
*c3 = *c2;
printf("c3 name: %s\n", c3->GetName());
delete c1;
delete c2;
delete c3;
//상속 객체의 복사, 대입
printf("==========================================\n");
//CHighElf(char* name, int lv=0) 호출
//따로 지정된 것이 있다. CCharacter(char* name) 호출.
CHighElf* h1 = new CHighElf("h1");
h1->Print();//이름 h1 정확이 들어가 있다.
//CHighElf(const CHighElf& h) 호출
//따로 지정된 것이 없기에 CCharacter()호출.
CHighElf* h2 = new CHighElf(*h1);
h2->Print();//name은 복사되지 않아 NULL이다.
//대입시 CHighElf의 맴버 변수만 복사처리 하기때문에 부모클래스의 것이 누락된다.
CHighElf* h3 = new CHighElf();
*h3 = *h1;
h3->Print();//name은 복사되지 않아 NULL이다.
//해결책은 해당 복사생성자와 대입연산자 구현부에 주석처리 되어있음
delete h1;
delete h2;
delete h3;
return 0;
}
{
protected:
char* m_name;
public:
CCharacter():m_name(0) {printf("CCharacter()\n");}
CCharacter(char* name)
{
m_name = new char[strlen(name)+1];
strcpy(m_name, name);
}
CCharacter(const CCharacter& c)
{
printf("CCharacter& c \n");
m_name = new char[strlen(c.m_name)+1];
strcpy(m_name, c.m_name);
}
~CCharacter() { delete[] m_name; }
CCharacter& operator=(const CCharacter& c)
{
printf("operator=\n");
if(this == &c) { return *this; }
if(m_name != NULL) { delete[] m_name; }
m_name = new char[strlen(c.m_name)+1];
strcpy(m_name, c.m_name);
return *this;
}
char* GetName() { return m_name; }
};
class CHighElf : public CCharacter
{
private:
int m_level;
public:
CHighElf():m_level(0) {}
CHighElf(char* name, int lv=0):CCharacter(name), m_level(lv) {}
CHighElf(const CHighElf& h):/*CCharacter(h),*/ m_level(h.m_level)
{
//괄호 위에 있는 CCharacter(h), 이 핵심
//이 부분이 괄호 위로 올라감으로 해서 CCharacter 기본 생성자가 호출되지 않고
//바로 CCharacter 복사 생성자가 호출.
//CCharacter::CCharacter(h); // 이렇게 하면 기본 생성자 호출
//m_level = h.m_level;
}
~CHighElf() {}
CHighElf& operator=(const CHighElf& h)
{
//CCharacter::operator=(h);//부모 클래스의 대입연산자도 호출해 줘야한다.
m_level = h.m_level;
return *this;
}
const int GetLevel() { return m_level; }
void Print() { printf("name: %s level: %d\n",m_name, m_level); }
};
int _tmain(int argc, _TCHAR* argv[])
{
//상속없는 객체의 복사, 대입
CCharacter* c1 = new CCharacter("c1");
printf("c1 name: %s\n", c1->GetName());
CCharacter* c2 = new CCharacter(*c1);
printf("c2 name: %s\n", c2->GetName());
CCharacter* c3 = new CCharacter();
*c3 = *c2;
printf("c3 name: %s\n", c3->GetName());
delete c1;
delete c2;
delete c3;
//상속 객체의 복사, 대입
printf("==========================================\n");
//CHighElf(char* name, int lv=0) 호출
//따로 지정된 것이 있다. CCharacter(char* name) 호출.
CHighElf* h1 = new CHighElf("h1");
h1->Print();//이름 h1 정확이 들어가 있다.
//CHighElf(const CHighElf& h) 호출
//따로 지정된 것이 없기에 CCharacter()호출.
CHighElf* h2 = new CHighElf(*h1);
h2->Print();//name은 복사되지 않아 NULL이다.
//대입시 CHighElf의 맴버 변수만 복사처리 하기때문에 부모클래스의 것이 누락된다.
CHighElf* h3 = new CHighElf();
*h3 = *h1;
h3->Print();//name은 복사되지 않아 NULL이다.
//해결책은 해당 복사생성자와 대입연산자 구현부에 주석처리 되어있음
delete h1;
delete h2;
delete h3;
return 0;
}
2015년 6월 16일 화요일
A Star 알고리즘 (길찾기)
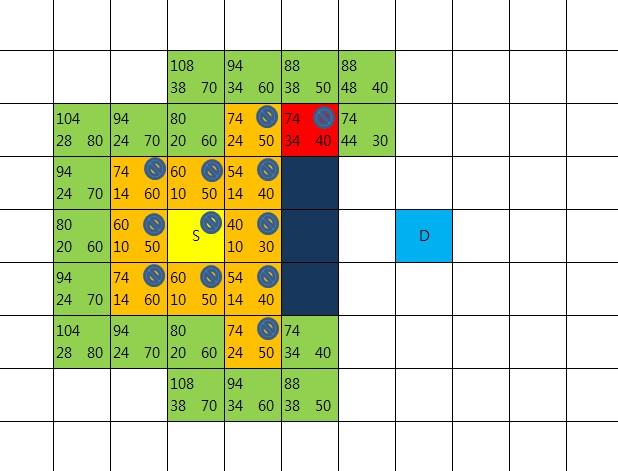
준비사항
전체 Map은 2차원 행렬로 구성
출발점(S), 목표지점(D)
openList , closeList 구성.
openList 는 길(Path)의 경로 중 하나가 될 가능성이 열려 있다는 뜻
closeList 는 반대로 이건 더이상 볼 필요 없다는 뜻
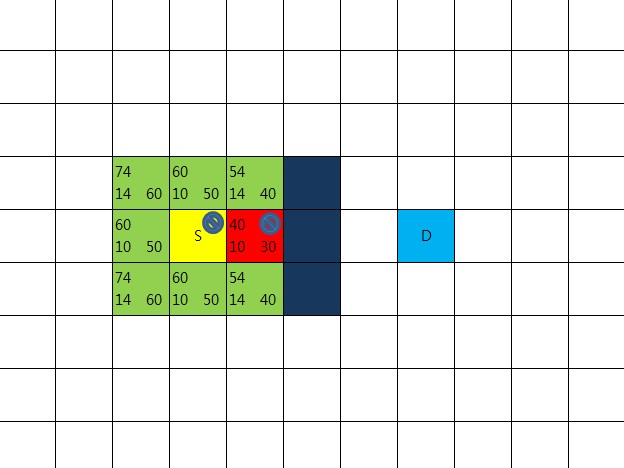
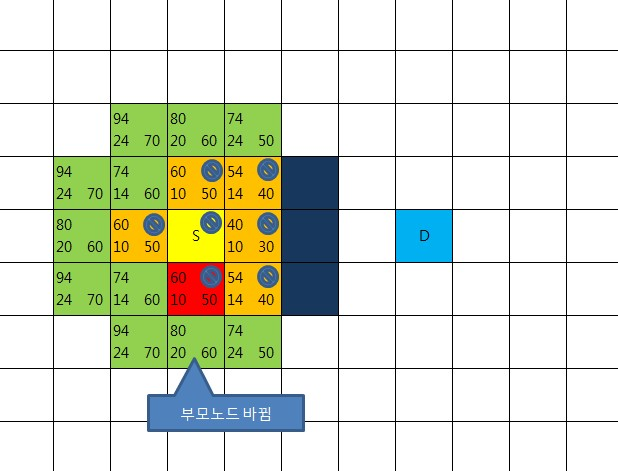
맵과, 출발점S, 도착점D, 중앙에 세개의 장애물 존재
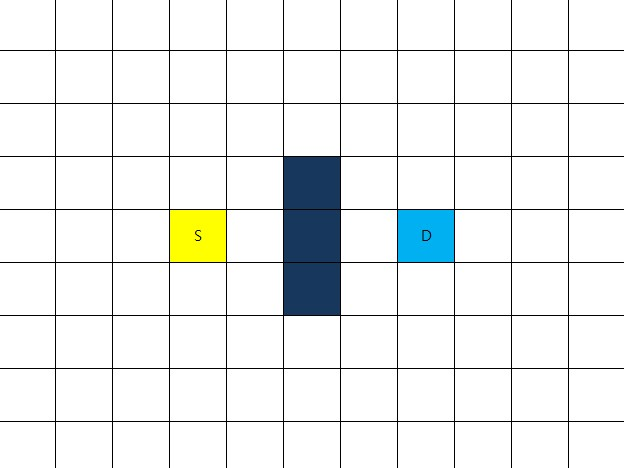
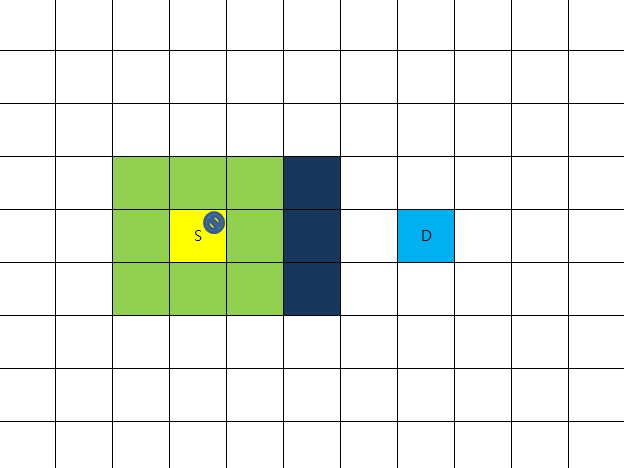
출발점을 우선 closeList에 추가한다.
그리고 8방향을 따져봤을때 다 갈수 있음을 알 수 있다.
이 8방향의 부모노드를 출발점으로 세팅해준다.
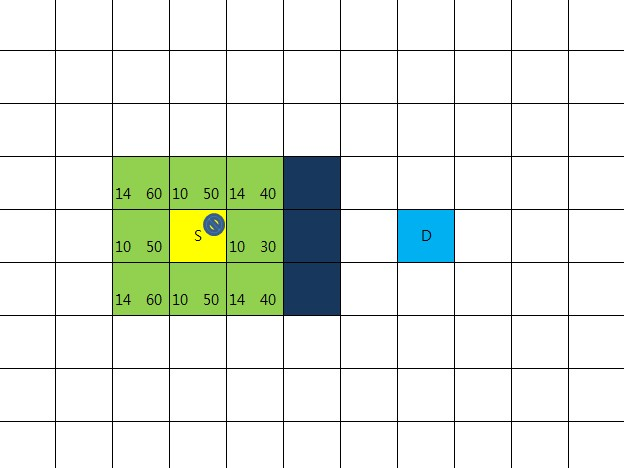
출발점으로 부터 8방향으로 이동하는 비용을 계산
수직, 수평 이동할 경우 10, 대각선 이동 할 경우 14를 적용한다.
이유는 말하지 않아도 알수있으리라(루트2 == 1.41414….)
비용을 사각 영역 왼쪽 아래에 기록( 이 비용을 R이라고 함 )
또 다른 비용 계산
8방향 각각으로 부터 D까지의 비용을 계산
이번엔 장애물의 존재 여부는 고려치 않고 수직,수평 이동만을 고려해서 계산
(대각이동은 없는 것으로 간주)
비용을 사각 영역 오른쪽 아래에 기록( 이 비용을 H 라고 함 )
총비용 F = R + H 으로 계산
사각 영역 왼쪽 상단에 기록
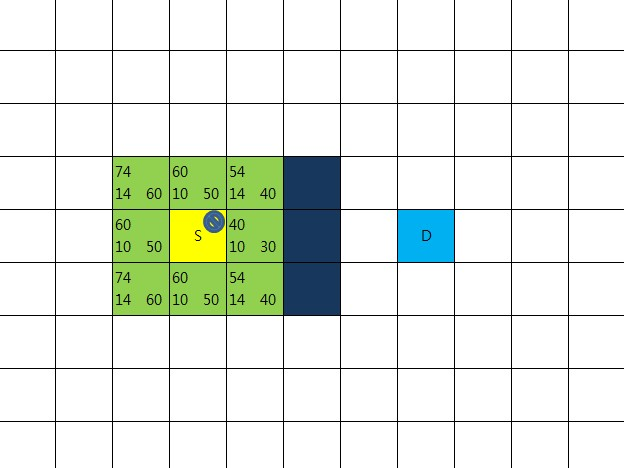
openList에 들어있는 지점들 중 총 비용이 가장 적은 곳을 선택
이 빨간 지점 중심으로 방금 한 일을 수행할 것이기 때문에
openList에서 제거하고 closeList에 넣는다.
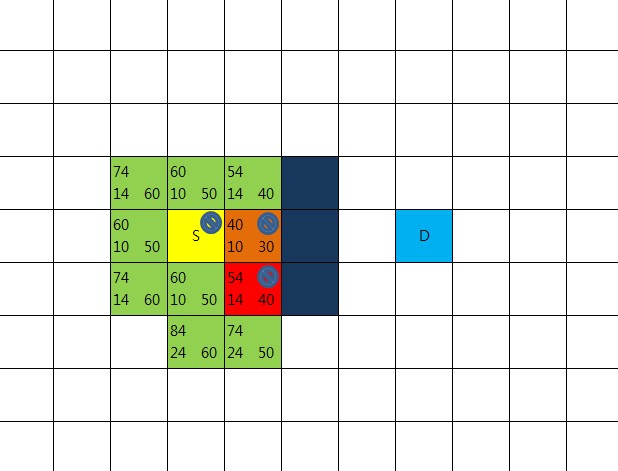
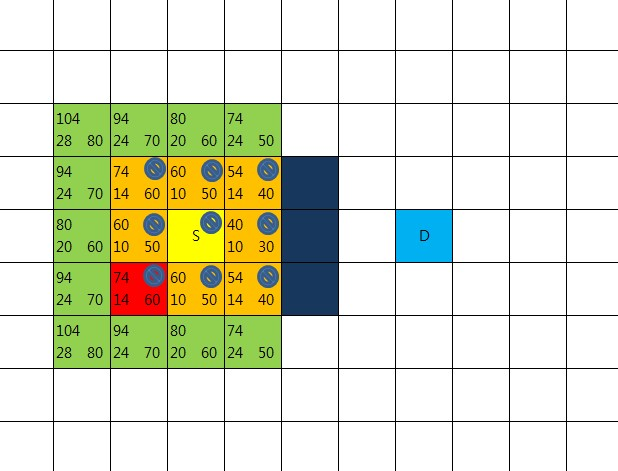
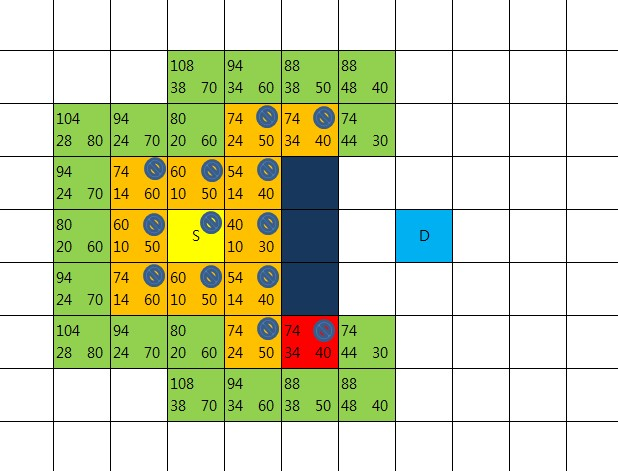
8방향 체크해 보니 새롭게 openList에 넣어야 할 지점이 없다.
이동 불가의 장애물,
closeList에 속한 지점,
이미 openList에 속한 지점 들 뿐이다.
그러나 한가지 확인해야 할 것이 있다.
이미 openList에 속한 지점 중에서 현재 중심이 되고 있는 빨간 지점을 거쳐서 갈 경우
기존의 R값 보다 더 적은 값이 나오는지를 확인해 봐야 한다.
만약 빨간 지점을 경유했을때 더 적은 R값이 나왔다면 기존의 부모노드를 버리고
빨간 지점을 부모노드로 설정해 준다.
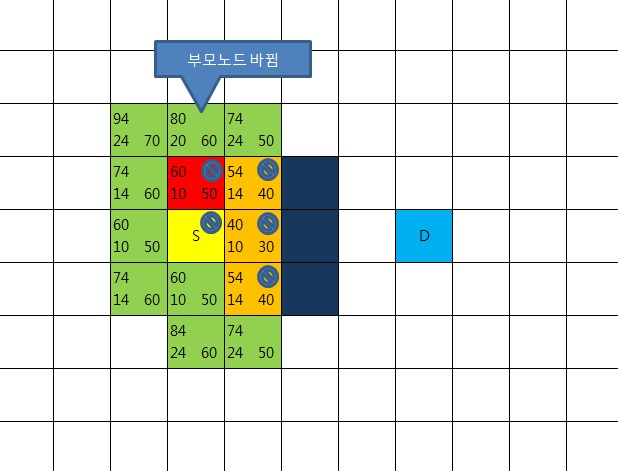
여기까지 작업했다면 새로운 중심점을 다시 선택하고 했던 작업을 반복한다.

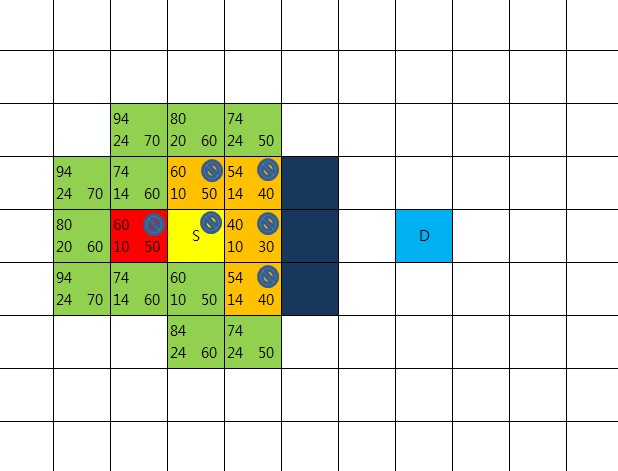

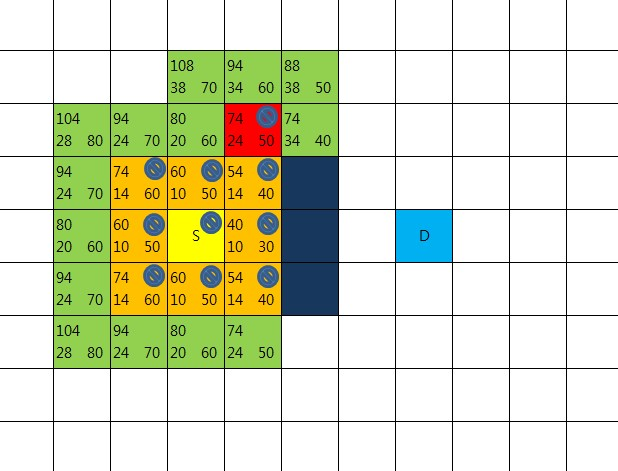
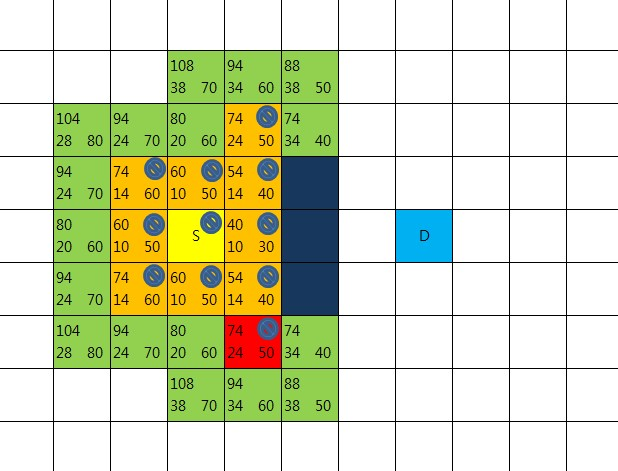
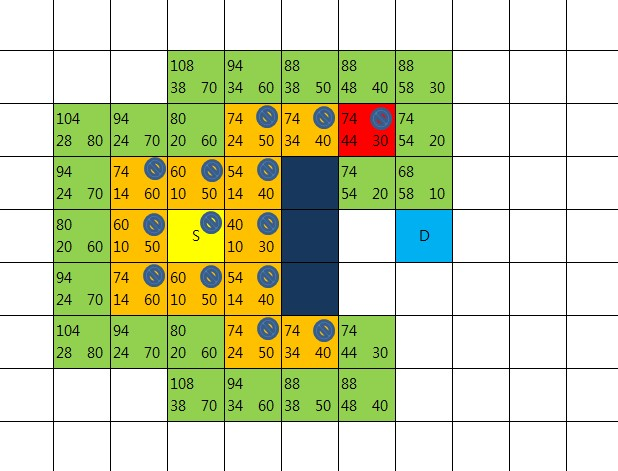
목표지점 D가 openList에 들어있는 것을 확인하는 순간 길은 찾아진 것이 된다.
지점D의 부모노드의 부모노드의 부모노드로 거쳐서 올라가다 보면
출발점이 나오기 때문이다.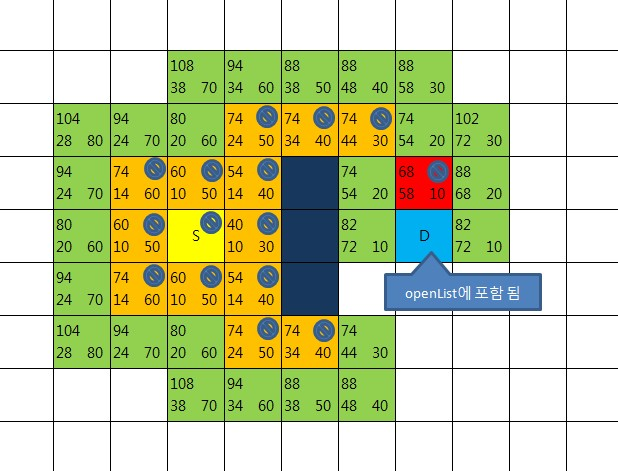
2015년 6월 14일 일요일
팩토리 패턴 (factory pattern)
우선 패턴의 형태
케릭터 ( 하이엘프, 휴먼 .. )
케릭터 메이커 ( 플레이어 메이커, 몬스터 메이커...)
만들어야 할 것들을 저렇게 구분 짓는다.
////////////////////////////////////////////////////////////////////////////////
우선 케릭터 부분에서 대략적인 활용 방법은
CCharacter pCharacter = pPlayerMaker->Create("HighElf");
pCharacter->무엇이든();
delete pCharacter;
이런 식으로 생성하고, 쓰이고, 삭제 될 것이다.
케릭터 클래스로 객체를 만들고 그 종류에 상관 없이 쓰이는 함수를 쓰다가 삭제
메이커 역시 그 종류에 상관없이 이름만 넣으면 적절한 케릭터를 만들어 주도록.
////////////////////////////////////////////////////////////////////////////////
우선 만드는 행동을 하려면 만들 것들이 대략적이나마 정해져 있어야 하니 정하자
#include <string>
class CCharacter
{
protected:
string m_strName;
virtual void LoadDate() = 0;
public:
string& GetName() { return m_strName; }
};
class CHighElf : public CCharacter
{
protected:
void LoadDate() {}
public:
CHighElf() { m_strName = "HighElf"; LoadDate(); }
};
class CHuman : public CCharacter
{
protected:
void LoadDate() {}
public:
CHuman () { m_strName = "Human"; LoadDate(); }
};
다 되었다면 메이커도 만들자
class CCharacterMaker
{
protected:
virtual CCharacter* Make(string& strType) = 0;//세부 메이커에서 구현
public:
CCharacter* Create(string& strType)
{
CCharacter* pCharacter = Make(strType);
return pCharacter;
}
};
class CPlayerMaker : public CCharacterMaker
{
protected:
CCharacter* Make(string& strType)
{
CCharacter* pCharacter = NULL;
if( strType == string("HighElf") )
{
pCharacter = new CHighElf();
}
else if( strType == string("Human") )
{
pCharacter = new CHuman();
}
return pCharacter;
}
};
이제 메인문에서 써먹어 보는 부분
int _tmain(int argc, _TCHAR* argv[])
{
CCharacter* pChar = NULL;
CCharacterMaker* pCharMaker = new CPlayerMaker();
pChar = pCharMaker->Create(string("HighElf"));
printf("%s 케릭터 생성\n", pCharacter->GetName().c_str());
delete pChar ;
return 0;
}
이것이 기본적인 팩토리 패턴이다.
이렇게 하면 케릭터를 만드는 부분에서 이름만 수정하면
다른부분, 예를 들면 행동하는 부분에서 코드를 수정하지 않아도 될것으로 보인다.
또한 개별 행동을 클래스 개별적으로 수정, 보완 할 수 있으니 다음에 찾아서 고쳐야 할때
찾기도 편하고 다시 이해 하기도 편할 것 같다.
2015년 6월 9일 화요일
연산자 오버로딩(operator)
이전부터 숙제로 남아있던 연산자 오버로딩에 덤벼보겠다
참고 사이트
#include <iostream>
using namespace std;
class A
{
private:
char* m_name;
int m_age;
public:
A() { cout<<"constructer-> A()"<<endl; m_name = 0; m_age=0; }
A(char* name, int age): m_age(age)
{
cout<<"constructer-> A(name,age)"<<endl;
m_name = new char[10];
strcpy(m_name, name);
}
A(A& copy)
{
cout<<"copy constructer-> A(A& copy)"<<endl;
m_age = copy.m_age;
m_name = new char[strlen(copy.m_name)+1];
strcpy(m_name, copy.m_name);
}
void ShowInfo()
{
cout << "이름: " << m_name << endl;
cout << "나이: " << m_age << endl;
}
A& operator=(A& ref)
{
cout<<"here="<<endl;
if(m_name == 0)
{ delete[] m_name; }
m_name = new char[10];
strcpy(m_name, ref.m_name);
m_age = ref.m_age;
return *this;
}
A& operator++()
{
cout<<"전위증가"<<endl;
m_age+=1;
return *this;
}
const A& operator++(int)
{
cout<<"후위증가"<<endl;
const A result(*this);
m_age+=1;
return result;
}
A& operator--()
{
cout<<"전위감소"<<endl;
m_age-=1;
return *this;
}
const A& operator--(int)
{
cout<<"후위감소"<<endl;
const A result(*this);
m_age-=1;
return result;
}
~A() { delete[] m_name; cout<< "~A()" << endl; }
};
int _tmain(int argc, _TCHAR* argv[])
{
// 지역변수로 객체를 만들경우 잘된다.
A a("a",1);
A b("b",2);
b = a; //오버로딩 된 연산자가 호출된다.
////////////////////////////////////////////////////////////
A* a = new A("a",1);
A* b = new A(*a);//복사생성자 이용하기 위해서는 a 아닌 *a로
A* c = new A();
c = a;//는 포인터라 연산자 호출이 안되고 디폴트 얕은 복사가 일어난다.
*c = *a; // 이렇게 해주면 연산자 호출이 된다.
c->ShowInfo();
////////////////////////////////////////////////////////////
--a;
a--;
++a;
a++;
return 0;
}
a = b 라는 것은
a.operator=(b) 라고 일반 함수 이해하듯 이해 해야 한다.
전위증가(감소)
후위증가(감소)
기록해 둠 () 안에 int를 적어두면 후위로 판단 하기로 약속이 되있다 함
참고 사이트
#include <iostream>
using namespace std;
class A
{
private:
char* m_name;
int m_age;
public:
A() { cout<<"constructer-> A()"<<endl; m_name = 0; m_age=0; }
A(char* name, int age): m_age(age)
{
cout<<"constructer-> A(name,age)"<<endl;
m_name = new char[10];
strcpy(m_name, name);
}
A(A& copy)
{
cout<<"copy constructer-> A(A& copy)"<<endl;
m_age = copy.m_age;
m_name = new char[strlen(copy.m_name)+1];
strcpy(m_name, copy.m_name);
}
void ShowInfo()
{
cout << "이름: " << m_name << endl;
cout << "나이: " << m_age << endl;
}
A& operator=(A& ref)
{
cout<<"here="<<endl;
if(m_name == 0)
{ delete[] m_name; }
m_name = new char[10];
strcpy(m_name, ref.m_name);
m_age = ref.m_age;
return *this;
}
A& operator++()
{
cout<<"전위증가"<<endl;
m_age+=1;
return *this;
}
const A& operator++(int)
{
cout<<"후위증가"<<endl;
const A result(*this);
m_age+=1;
return result;
}
A& operator--()
{
cout<<"전위감소"<<endl;
m_age-=1;
return *this;
}
const A& operator--(int)
{
cout<<"후위감소"<<endl;
const A result(*this);
m_age-=1;
return result;
}
~A() { delete[] m_name; cout<< "~A()" << endl; }
};
int _tmain(int argc, _TCHAR* argv[])
{
// 지역변수로 객체를 만들경우 잘된다.
A a("a",1);
A b("b",2);
b = a; //오버로딩 된 연산자가 호출된다.
////////////////////////////////////////////////////////////
A* a = new A("a",1);
A* b = new A(*a);//복사생성자 이용하기 위해서는 a 아닌 *a로
A* c = new A();
c = a;//는 포인터라 연산자 호출이 안되고 디폴트 얕은 복사가 일어난다.
*c = *a; // 이렇게 해주면 연산자 호출이 된다.
c->ShowInfo();
////////////////////////////////////////////////////////////
--a;
a--;
++a;
a++;
return 0;
}
a = b 라는 것은
a.operator=(b) 라고 일반 함수 이해하듯 이해 해야 한다.
전위증가(감소)
후위증가(감소)
기록해 둠 () 안에 int를 적어두면 후위로 판단 하기로 약속이 되있다 함
스마트포인터(shared_ptr)
참고 사이트
#include <memory> 필요
#include <memory> 필요
class CA;
typedef std::tr1::shared_ptr<CA> pCA;
typedef std::tr1::shared_ptr<char> pChar;
class CA
{
private:
int m_int;
public:
CA():m_int(0) { printf("CA()\n"); }
CA(const CA& a):m_int(a.m_int) { printf("CA(const CA& a)\n"); }
~CA(){printf("~CA()\n");}
pCA GetThis() { return pCA(this); }
int GetInt() { return m_int; }
};
struct DeletArray
{
template<typename T>
void operator()(T* t)
{
printf("DeleteArray is called\n");
delete [] t;
}
};
struct DontDelete
{
template<typename T>
void operator()(T* t) {printf("DontDelete is called\n");}
};
int _tmain(int argc, _TCHAR* argv[])
{
//단순한 포인터 클래스 객체
pCA p1(new CA());
pCA p2(new CA(*p1));
//복사도 잘되고 잘 지워짐
//배열형태의 포인터
pChar p3(new char[10], DeletArray());
//DeletArray()로 삭제처리를 설정해 delete 가 아닌 delete[] 로 삭제된다.
//지워지면 안되는 포인터 클래스 객체, 다른 관리자에게 위임 되거나 하는 경우
pCA p4(new CA(), DontDelete());
return 0;
}
typedef std::tr1::shared_ptr<CA> pCA;
typedef std::tr1::shared_ptr<char> pChar;
class CA
{
private:
int m_int;
public:
CA():m_int(0) { printf("CA()\n"); }
CA(const CA& a):m_int(a.m_int) { printf("CA(const CA& a)\n"); }
~CA(){printf("~CA()\n");}
pCA GetThis() { return pCA(this); }
int GetInt() { return m_int; }
};
struct DeletArray
{
template<typename T>
void operator()(T* t)
{
printf("DeleteArray is called\n");
delete [] t;
}
};
struct DontDelete
{
template<typename T>
void operator()(T* t) {printf("DontDelete is called\n");}
};
int _tmain(int argc, _TCHAR* argv[])
{
//단순한 포인터 클래스 객체
pCA p1(new CA());
pCA p2(new CA(*p1));
//복사도 잘되고 잘 지워짐
//배열형태의 포인터
pChar p3(new char[10], DeletArray());
//DeletArray()로 삭제처리를 설정해 delete 가 아닌 delete[] 로 삭제된다.
//지워지면 안되는 포인터 클래스 객체, 다른 관리자에게 위임 되거나 하는 경우
pCA p4(new CA(), DontDelete());
return 0;
}
2015년 6월 4일 목요일
STL 시퀀스 알고리즘
참고 사이트
어차피 선형의 시간복잡도라면 힘들게 for문 만드는거 보다
이걸 쓰는게 더 생선적인거 같아 잊지 않기 위해 기록해 둔다.
필요한 해더로는
#include <iostream> //->이건 단순히 프린트 용
#include <algorithm> // find 등의 시퀀스 알고리즘 관련된 듯
#include <vector> // 여기서는 벡터만 이용
using namespace std;
0. 어떤 것들이 있을까?
find, find_if
//////////////////////////////////////////////////////////////////////////////////////////////
1. find
//벡터의 시작, 끝, 찾고싶은 값을 이용해 해당 것을 찾아냄
main
{
vector<int> number;
number.push_back(10);
number.push_back(20);
number.push_back(30);
vector<int>::iterator iter = find(number.begin(), number.end(), 10);
cout<< "찾은것: "<< *iter << endl;
}
//////////////////////////////////////////////////////////////////////////////////////////////
2. find_if
//조건을 담은 별도의 함수 이용, 이 함수는 bool 값을 리턴
//벡터를 순회하며 최초의 true값인 것을 찾아낸다.
->별도의 함수
bool BiggerThan30(int i)
{
//if문도 필요 없구나....
return ( i > 30);
}
main
{
vector<int> number;
number.push_back(10);
number.push_back(60);
number.push_back(20);
number.push_back(30);
vector<int>::iterator iter = find_if(number.begin(), number.end(), BiggerThan30);
cout<< "찾은것: "<< *iter << endl;
}
//////////////////////////////////////////////////////////////////////////////////////////////
3. adjacent_find
//동일원소가 이웃하고 있으면 그 첫번째 원소의 이터레이터를 리턴한다.
//조건자를 추가할 경우 그에 맞는 값을 리턴한다.
main
{
vector<int> number;
number.push_back(10);//1
number.push_back(70);//2
number.push_back(30);//3
number.push_back(20);//4
number.push_back(20);//5
number.push_back(10);//6
vector<int>::iterator iter = adjacent_find(number.begin(), number.end());
cout<<"찾은것: "<< *iter <<endl;
cout<<"다음것: "<< *(++iter) <<endl;
iter = adjacent_find(number.begin(), number.end(), greater<int>() );
cout<<"여기에 들어갈 값: "<< *iter <<endl;
}
첫번째는 4번을 리턴한다. 비조건자 버전은 비교시 string::operator== 를 사용해서 동일 원소가 인접한 첫번째 쌍의 첫번째 원소를 찾는다.
두번째는 조건자 greater<int>()를 사용하여 비교 수행 ( current > right ? ) 고로 첫번째로
오른쪽 보다 큰 값 70이 리턴된다.
//////////////////////////////////////////////////////////////////////////////////////////////
4. count
// 특정 값과 일치하는 원소의 개수를 세는 알고리즘
bool Func(int i)
{
return (i % 20 == 0);
}
main
{
vector<int> number;
number.push_back(10);
number.push_back(20);
number.push_back(30);
number.push_back(20);
number.push_back(20);
number.push_back(10);
int c = count(number.begin(), number.end(), 20);
int c = count(number.begin(), number.end(), 20);
cout<<"20의 개수: "<< c <<endl;
int c_if = count_if(number.begin(), number.end(), Func);
cout<<"20으로 똑 나누어 떨어지는것 개수: "<< c_if <<endl;
}
//////////////////////////////////////////////////////////////////////////////////////////////
5. for_each
//stl 원소들을 순회
void Print(int i)
{
cout<< i <<endl;
}
main
{
vector<int> number;
number.push_back(10);
number.push_back(20);
number.push_back(30);
number.push_back(20);
number.push_back(60);
number.push_back(10);
for_each(number.begin(), number.end(), Print);
}
//////////////////////////////////////////////////////////////////////////////////////////////
5. equal , mismatch
//stl 간 비교 시 쓰임
#include <string>// 추가
main
{
vector<string> aVector;
vector<string> bVector;
vector<string> cVector;
aVector.push_back("A");
aVector.push_back("B");
aVector.push_back("C");
bVector.push_back("A");
bVector.push_back("B");
bVector.push_back("C");
bVector.push_back("D");
cVector.push_back("A");
cVector.push_back("D");
if( equal(aVector.begin(), aVector.end(), bVector.begin()) == true )
{
int size = aVector.size();
cout<< "aVector와 bVector의 처음 " << size << "개의 원소 일치"<< endl;
}
else
{
cout<< "aVector와 bVector는 같지 않습니다."<< endl;
}
//위에서 처럼 기준이 되는 aVector의 원소의 개수(size)가 bVector의 것과 다를 경우
//앞의 세개가 같아도 결국 같은 내용을 담고 있다는 것을 보증할 수 없으니
//내용 비교 전 사이즈 비교를 해줘야 한다.
if( aVector.size() == bVector.size() &&
equal(aVector.begin(), aVector.end(), bVector.begin())
{
//같음
}
else
{
//다름
}
pair<vector<string>::iterator, vector<string>::iterator>
p = mismatch(cVector.begin(), cVector.end(), aVector.begin());
if( p.first != cVector.end() )
{
cout<< "첫 불일치 리스트 cVector의 "<< *p.first<<
" 와 aVector의 "<< *p.second << endl;
}
}
//////////////////////////////////////////////////////////////////////////////////////////////
6. search
// 두 stl 간에 들어있는 데이터의 시퀀스가 일치하는 부분이 있으면 그 첫 시작점의 이터레이터를 리턴한다.
#include <deque>//추가
main
{
vector<int> vector1(20);
deque<int> deque1(5);
for(int i=0; i< 20; ++i)
{ vector1[i] = i; }
for(int i=0; i<5; ++i)
{ deque1[i] = i+5; }
//vector1에서 deque에 들어있는 내용과 같은 부분을 찾겠다는 것임
vector<int>::iterator iter =
search(vector1.begin(), vector1.end(), deque1.begin(), deque1.end());
int count = deque1.size();
for(int i=0; i<count; ++i)
{
cout<< *(iter+i) <<endl;
}
}
어차피 선형의 시간복잡도라면 힘들게 for문 만드는거 보다
이걸 쓰는게 더 생선적인거 같아 잊지 않기 위해 기록해 둔다.
필요한 해더로는
#include <iostream> //->이건 단순히 프린트 용
#include <algorithm> // find 등의 시퀀스 알고리즘 관련된 듯
#include <vector> // 여기서는 벡터만 이용
using namespace std;
0. 어떤 것들이 있을까?
find, find_if
//////////////////////////////////////////////////////////////////////////////////////////////
1. find
//벡터의 시작, 끝, 찾고싶은 값을 이용해 해당 것을 찾아냄
main
{
vector<int> number;
number.push_back(10);
number.push_back(20);
number.push_back(30);
vector<int>::iterator iter = find(number.begin(), number.end(), 10);
cout<< "찾은것: "<< *iter << endl;
}
//////////////////////////////////////////////////////////////////////////////////////////////
2. find_if
//조건을 담은 별도의 함수 이용, 이 함수는 bool 값을 리턴
//벡터를 순회하며 최초의 true값인 것을 찾아낸다.
->별도의 함수
bool BiggerThan30(int i)
{
//if문도 필요 없구나....
return ( i > 30);
}
main
{
vector<int> number;
number.push_back(10);
number.push_back(60);
number.push_back(20);
number.push_back(30);
vector<int>::iterator iter = find_if(number.begin(), number.end(), BiggerThan30);
cout<< "찾은것: "<< *iter << endl;
}
//////////////////////////////////////////////////////////////////////////////////////////////
3. adjacent_find
//동일원소가 이웃하고 있으면 그 첫번째 원소의 이터레이터를 리턴한다.
main
{
vector<int> number;
number.push_back(10);//1
number.push_back(70);//2
number.push_back(30);//3
number.push_back(20);//4
number.push_back(20);//5
number.push_back(10);//6
vector<int>::iterator iter = adjacent_find(number.begin(), number.end());
cout<<"찾은것: "<< *iter <<endl;
cout<<"다음것: "<< *(++iter) <<endl;
iter = adjacent_find(number.begin(), number.end(), greater<int>() );
cout<<"여기에 들어갈 값: "<< *iter <<endl;
}
첫번째는 4번을 리턴한다. 비조건자 버전은 비교시 string::operator== 를 사용해서 동일 원소가 인접한 첫번째 쌍의 첫번째 원소를 찾는다.
두번째는 조건자 greater<int>()를 사용하여 비교 수행 ( current > right ? ) 고로 첫번째로
오른쪽 보다 큰 값 70이 리턴된다.
//////////////////////////////////////////////////////////////////////////////////////////////
4. count
// 특정 값과 일치하는 원소의 개수를 세는 알고리즘
bool Func(int i)
{
return (i % 20 == 0);
}
main
{
vector<int> number;
number.push_back(10);
number.push_back(20);
number.push_back(30);
number.push_back(20);
number.push_back(20);
number.push_back(10);
int c = count(number.begin(), number.end(), 20);
int c = count(number.begin(), number.end(), 20);
cout<<"20의 개수: "<< c <<endl;
int c_if = count_if(number.begin(), number.end(), Func);
cout<<"20으로 똑 나누어 떨어지는것 개수: "<< c_if <<endl;
}
//////////////////////////////////////////////////////////////////////////////////////////////
5. for_each
//stl 원소들을 순회
void Print(int i)
{
cout<< i <<endl;
}
main
{
vector<int> number;
number.push_back(10);
number.push_back(20);
number.push_back(30);
number.push_back(20);
number.push_back(60);
number.push_back(10);
for_each(number.begin(), number.end(), Print);
}
//////////////////////////////////////////////////////////////////////////////////////////////
5. equal , mismatch
//stl 간 비교 시 쓰임
#include <string>// 추가
main
{
vector<string> aVector;
vector<string> bVector;
vector<string> cVector;
aVector.push_back("A");
aVector.push_back("B");
aVector.push_back("C");
bVector.push_back("A");
bVector.push_back("B");
bVector.push_back("C");
bVector.push_back("D");
cVector.push_back("A");
cVector.push_back("D");
if( equal(aVector.begin(), aVector.end(), bVector.begin()) == true )
{
int size = aVector.size();
cout<< "aVector와 bVector의 처음 " << size << "개의 원소 일치"<< endl;
}
else
{
cout<< "aVector와 bVector는 같지 않습니다."<< endl;
}
//위에서 처럼 기준이 되는 aVector의 원소의 개수(size)가 bVector의 것과 다를 경우
//앞의 세개가 같아도 결국 같은 내용을 담고 있다는 것을 보증할 수 없으니
//내용 비교 전 사이즈 비교를 해줘야 한다.
if( aVector.size() == bVector.size() &&
equal(aVector.begin(), aVector.end(), bVector.begin())
{
//같음
}
else
{
//다름
}
pair<vector<string>::iterator, vector<string>::iterator>
if( p.first != cVector.end() )
{
cout<< "첫 불일치 리스트 cVector의 "<< *p.first<<
" 와 aVector의 "<< *p.second << endl;
}
}
//////////////////////////////////////////////////////////////////////////////////////////////
6. search
// 두 stl 간에 들어있는 데이터의 시퀀스가 일치하는 부분이 있으면 그 첫 시작점의 이터레이터를 리턴한다.
#include <deque>//추가
main
{
vector<int> vector1(20);
deque<int> deque1(5);
for(int i=0; i< 20; ++i)
{ vector1[i] = i; }
for(int i=0; i<5; ++i)
{ deque1[i] = i+5; }
//vector1에서 deque에 들어있는 내용과 같은 부분을 찾겠다는 것임
vector<int>::iterator iter =
search(vector1.begin(), vector1.end(), deque1.begin(), deque1.end());
int count = deque1.size();
for(int i=0; i<count; ++i)
{
cout<< *(iter+i) <<endl;
}
}
Template(테플릿)
공부중
template <typename T1, typenameT2>
void ShowData(T1 a, T2 b)
{
cout<< a <<" ";
cout<< b <<endl;
}
이렇게 하면 a나 b에 int가 들어오든 float이 들어오든 상관 없이 실행됨
template <typename T1, typenameT2>
void ShowData(T1 a, T2 b)
{
cout<< a <<" ";
cout<< b <<endl;
}
이렇게 하면 a나 b에 int가 들어오든 float이 들어오든 상관 없이 실행됨
2015년 6월 3일 수요일
QuickSort
1 7 2 8 6 9 3 5 4
명칭이 quick sort라고 다 똑같은 방법은 아닌거 같음
중간값 예) 6을 선택하고 좌, 우에서 그 보다 큰 혹은 작은 수를 잡고 서로 바꿔 가는
방법이 있으나 선호하지 않음
내가 선호하는 방법은 첫 원소를 잡고 그 원소의 최종 자리를 찾을때 까지 비교 하는 것
시작
1번째 원소를 피봇으로 선택
1 7 2 8 6 9 3 5 4
9번째(마지막) 원소를 비교대상으로 선택
1 7 2 8 6 9 3 5 4
1 7 2 8 6 9 3 5 4 -> 1 과 4 비교 바꿀 필요 없음
비교대상 진행 방향 왼쪽
1 7 2 8 6 9 3 5 4 -> 1 과 5 비교 바꿀 필요 없음
1 7 2 8 6 9 3 5 4 -> 1 과 3 비교 바꿀 필요 없음
1 7 2 8 6 9 3 5 4 -> 1 과 9 비교 바꿀 필요 없음
1 7 2 8 6 9 3 5 4 -> 1 과 6 비교 바꿀 필요 없음
1 7 2 8 6 9 3 5 4 -> 1 과 8 비교 바꿀 필요 없음
1 7 2 8 6 9 3 5 4 -> 1 과 2 비교 바꿀 필요 없음
1 7 2 8 6 9 3 5 4 -> 1 과 7 비교 바꿀 필요 없음
1은 자리 확정!
1 7 2 8 6 9 3 5 4 -> 7 과 4 비교 바꿈
1 4 2 8 6 9 3 5 7 -> 비교대상 진행 방향 오른쪽
1 4 2 8 6 9 3 5 7 -> 7 과 2 비교 바꿀 필요 없음
1 4 2 8 6 9 3 5 7 -> 7 과 8 비교 바꿈
1 4 2 7 6 9 3 5 8 -> 비교대상 진행 방향 왼쪽
1 4 2 7 6 9 3 5 8 -> 7 과 5 비교 바꿈
1 4 2 5 6 9 3 7 8 -> 비교대상 진행 방향 오른쪽
1 4 2 5 6 9 3 7 8 -> 7 과 6 비교 바꿀 필요 없음
1 4 2 5 6 9 3 7 8 -> 7 과 9 비교 바꿈
1 4 2 5 6 7 3 9 8 -> 비교대상 진행 방향 왼쪽
1 4 2 5 6 7 3 9 8 -> 7 과 3 비교 바꿈
1 4 2 5 6 3 7 9 8 -> 비교대상 진행 방향 오른쪽
다음 비교대상 자기 자신이 되니까( 비교대상 없음 )
7번 자리 확정!!
1 4 2 5 6 3 7 9 8 -> 4 과 3 비교 바꿈
1 3 2 5 6 4 7 9 8 -> 비교대상 진행 방향 오른쪽
1 3 2 5 6 4 7 9 8 -> 4 과 2 비교 바꿀 필요 없음
1 3 2 5 6 4 7 9 8 -> 4 과 5 비교 바꿈
1 3 2 4 6 5 7 9 8 -> 비교대상 진행 방향 왼쪽
1 3 2 4 6 5 7 9 8 -> 4 과 6 비교 바꿀 필요 없음
다음 비교대상 자기 자신이 되니까( 비교대상 없음 )
4번 자리 확정!!
1 3 2 4 6 5 7 9 8 -> 3 과 2 비교 바꿈
1 2 3 4 6 5 7 9 8 -> 3 과 2 비교 바꿈
다음 비교대상 자기 자신이 되니까( 비교대상 없음 )
3번 자리 확정!!
1 2 3 4 6 5 7 9 8 -> 2 혼자있음 확정
2번 자리 확정!!
1 2 3 4 6 5 7 9 8 -> 6 과 5 비교 바꿈
1 2 3 4 5 6 7 9 8 -> 비교대상 진행 방향 오른쪽
다음 비교대상 자기 자신이 되니까( 비교대상 없음 )
6번 자리 확정!!
이런 식으로 자리가 확정 된 원소들은 칸막이 역할을 하게 돼
이 후 복잡함이 한결 줄어든다.
참고 영상 링크
시간복잡도 설명(링크)
O(1) – 상수 시간 : 문제를 해결하는데 오직 한 단계만 처리함.
O(log n) – 로그 시간 : 문제를 해결하는데 필요한 단계들이 연산마다 특정 요인에 의해 줄어듬.
O(n) – 직선적 시간 : 문제를 해결하기 위한 단계의 수와 입력값 n이 1:1 관계를 가짐.
O(n log n) : 문제를 해결하기 위한 단계의 수가 N*(log2N) 번만큼의 수행시간을 가진다. (선형로그형)
O(n^2) – 2차 시간 : 문제를 해결하기 위한 단계의 수는 입력값 n의 제곱.
O(C^n) – 지수 시간 : 문제를 해결하기 위한 단계의 수는 주어진 상수값 C 의 n 제곱.
명칭이 quick sort라고 다 똑같은 방법은 아닌거 같음
중간값 예) 6을 선택하고 좌, 우에서 그 보다 큰 혹은 작은 수를 잡고 서로 바꿔 가는
방법이 있으나 선호하지 않음
내가 선호하는 방법은 첫 원소를 잡고 그 원소의 최종 자리를 찾을때 까지 비교 하는 것
시작
1번째 원소를 피봇으로 선택
1 7 2 8 6 9 3 5 4
9번째(마지막) 원소를 비교대상으로 선택
1 7 2 8 6 9 3 5 4
1 7 2 8 6 9 3 5 4 -> 1 과 4 비교 바꿀 필요 없음
비교대상 진행 방향 왼쪽
1 7 2 8 6 9 3 5 4 -> 1 과 5 비교 바꿀 필요 없음
1 7 2 8 6 9 3 5 4 -> 1 과 3 비교 바꿀 필요 없음
1 7 2 8 6 9 3 5 4 -> 1 과 9 비교 바꿀 필요 없음
1 7 2 8 6 9 3 5 4 -> 1 과 6 비교 바꿀 필요 없음
1 7 2 8 6 9 3 5 4 -> 1 과 8 비교 바꿀 필요 없음
1 7 2 8 6 9 3 5 4 -> 1 과 2 비교 바꿀 필요 없음
1 7 2 8 6 9 3 5 4 -> 1 과 7 비교 바꿀 필요 없음
1은 자리 확정!
1 7 2 8 6 9 3 5 4 -> 7 과 4 비교 바꿈
1 4 2 8 6 9 3 5 7 -> 비교대상 진행 방향 오른쪽
1 4 2 8 6 9 3 5 7 -> 7 과 2 비교 바꿀 필요 없음
1 4 2 8 6 9 3 5 7 -> 7 과 8 비교 바꿈
1 4 2 7 6 9 3 5 8 -> 비교대상 진행 방향 왼쪽
1 4 2 7 6 9 3 5 8 -> 7 과 5 비교 바꿈
1 4 2 5 6 9 3 7 8 -> 비교대상 진행 방향 오른쪽
1 4 2 5 6 9 3 7 8 -> 7 과 6 비교 바꿀 필요 없음
1 4 2 5 6 9 3 7 8 -> 7 과 9 비교 바꿈
1 4 2 5 6 7 3 9 8 -> 비교대상 진행 방향 왼쪽
1 4 2 5 6 7 3 9 8 -> 7 과 3 비교 바꿈
1 4 2 5 6 3 7 9 8 -> 비교대상 진행 방향 오른쪽
다음 비교대상 자기 자신이 되니까( 비교대상 없음 )
7번 자리 확정!!
1 4 2 5 6 3 7 9 8 -> 4 과 3 비교 바꿈
1 3 2 5 6 4 7 9 8 -> 비교대상 진행 방향 오른쪽
1 3 2 5 6 4 7 9 8 -> 4 과 2 비교 바꿀 필요 없음
1 3 2 5 6 4 7 9 8 -> 4 과 5 비교 바꿈
1 3 2 4 6 5 7 9 8 -> 비교대상 진행 방향 왼쪽
1 3 2 4 6 5 7 9 8 -> 4 과 6 비교 바꿀 필요 없음
다음 비교대상 자기 자신이 되니까( 비교대상 없음 )
4번 자리 확정!!
1 3 2 4 6 5 7 9 8 -> 3 과 2 비교 바꿈
1 2 3 4 6 5 7 9 8 -> 3 과 2 비교 바꿈
다음 비교대상 자기 자신이 되니까( 비교대상 없음 )
3번 자리 확정!!
1 2 3 4 6 5 7 9 8 -> 2 혼자있음 확정
2번 자리 확정!!
1 2 3 4 6 5 7 9 8 -> 6 과 5 비교 바꿈
1 2 3 4 5 6 7 9 8 -> 비교대상 진행 방향 오른쪽
다음 비교대상 자기 자신이 되니까( 비교대상 없음 )
6번 자리 확정!!
이런 식으로 자리가 확정 된 원소들은 칸막이 역할을 하게 돼
이 후 복잡함이 한결 줄어든다.
참고 영상 링크
시간복잡도 설명(링크)
O(1) – 상수 시간 : 문제를 해결하는데 오직 한 단계만 처리함.
O(log n) – 로그 시간 : 문제를 해결하는데 필요한 단계들이 연산마다 특정 요인에 의해 줄어듬.
O(n) – 직선적 시간 : 문제를 해결하기 위한 단계의 수와 입력값 n이 1:1 관계를 가짐.
O(n log n) : 문제를 해결하기 위한 단계의 수가 N*(log2N) 번만큼의 수행시간을 가진다. (선형로그형)
O(n^2) – 2차 시간 : 문제를 해결하기 위한 단계의 수는 입력값 n의 제곱.
O(C^n) – 지수 시간 : 문제를 해결하기 위한 단계의 수는 주어진 상수값 C 의 n 제곱.
2015년 6월 2일 화요일
ShellSort
1 7 2 8 6 9 3 5 4
insert sort는 바로 앞에꺼와 비교했다면
shell sort 는 바로 앞이 아닌 인터벌을 두고 비교
저 뒤에 잘못 배치된 놈이 한방에 제자리로 갈수도 있는 효율적 상황을 기대해 보자!
고로 비교 간격 설정부터!
참고사이트2
h(1) = 1;
h(i+1) = 3* h(i) + 1; 을 거쳐 나온 1, 4, 13, 40, 121, 364, 1093, 3280...순
잘 알려진 optimal sequence로 다음 두 가지를 알아두자.
1. Sedgewick : 1 3 7 21 48 112 336 861 1968 4592
2. Papernov-Stasevic : 1 3 7 15 31 63 127 255 511 1023 2047
여기서는 비교간격 k = n/2 = 9/2 = 4
1 7 2 8 6 9 3 5 4
>Step 1 ( k=4 )
1 7 2 8 // 6 9 3 5 // 4 -> 1 과 6 비교 바꿀 필요 없음
1 7 2 8 // 6 9 3 5 // 4 -> 6 과 4 비교 바꿈
1 7 2 8 // 4 9 3 5 // 6
1 7 2 8 // 4 9 3 5 // 6 -> 7 과 9 비교 바꿀 필요 없음
1 7 2 8 // 4 9 3 5 // 6 -> 2 과 3 비교 바꿀 필요 없음
1 7 2 8 // 4 9 3 5 // 6 -> 8 과 5 비교 바꿈
1 7 2 5 // 4 9 3 8 // 6
>Step 2 ( k=2 )
1 7 // 2 5 // 4 9 // 3 8 // 6 -> 1 과 2 비교 바꿀 필요 없음
1 7 // 2 5 // 3 9 // 4 8 // 6
1 7 // 2 5 // 3 9 // 4 8 // 6 -> 4 과 6 비교 바꿀 필요 없음
1 7 // 2 5 // 3 9 // 4 8 // 6 -> 7 과 5 비교 바꿈
1 5 // 2 7 // 3 9 // 4 8 // 6
1 5 // 2 7 // 3 9 // 4 8 // 6 -> 7 과 9 비교 바꿀 필요 없음
1 5 // 2 7 // 3 9 // 4 8 // 6 -> 9 과 8 비교 바꿈
1 5 // 2 7 // 3 8 // 4 9 // 6
>Step 3 ( k=1 ) !! 여기서 부터는 Insert Sort
1 5 2 7 3 8 4 9 6 -> 1 과 5 비교 바꿀 필요 없음
1 5 2 7 3 8 4 9 6 -> 5 과 2 비교 바꿈
1 2 5 7 3 8 4 9 6
1 2 5 7 3 8 4 9 6 -> 1 과 2 비교 바꿀 필요 없음
1 2 5 7 3 8 4 9 6 -> 5 과 7 비교 바꿀 필요 없음
1 2 5 7 3 8 4 9 6 -> 7 과 3 비교 바꿈
1 2 5 3 7 8 4 9 6
1 2 5 3 7 8 4 9 6 -> 5 과 3 비교 바꿈
1 2 3 5 7 8 4 9 6
1 2 3 5 7 8 4 9 6 -> 2 과 3 비교 바꿀 필요 없음
다음은 8 그 다음은 4 그 다음은 9 순으로 비교
참고 영상 링크
영상은 스타일이 좀 다릅니다
insert sort는 바로 앞에꺼와 비교했다면
shell sort 는 바로 앞이 아닌 인터벌을 두고 비교
저 뒤에 잘못 배치된 놈이 한방에 제자리로 갈수도 있는 효율적 상황을 기대해 보자!
고로 비교 간격 설정부터!
Donald Shell은 처음에 간격을 2^k, (k는 0 이상의 자연수) 혹은 2^k-1로 잡았으며,
Marcin Ciura의 연구에 의하면 1, 4, 10, 23, 57, 132, 301, 701, 1750 ... 과 같은 간격을 사용하는 것이
연산 시간을 많이 줄인다고 한다.
참고사이트2
h(1) = 1;
h(i+1) = 3* h(i) + 1; 을 거쳐 나온 1, 4, 13, 40, 121, 364, 1093, 3280...순
잘 알려진 optimal sequence로 다음 두 가지를 알아두자.
1. Sedgewick : 1 3 7 21 48 112 336 861 1968 4592
2. Papernov-Stasevic : 1 3 7 15 31 63 127 255 511 1023 2047
여기서는 비교간격 k = n/2 = 9/2 = 4
1 7 2 8 6 9 3 5 4
>Step 1 ( k=4 )
1 7 2 8 // 6 9 3 5 // 4 -> 1 과 6 비교 바꿀 필요 없음
1 7 2 8 // 6 9 3 5 // 4 -> 6 과 4 비교 바꿈
1 7 2 8 // 4 9 3 5 // 6
1 7 2 8 // 4 9 3 5 // 6 -> 7 과 9 비교 바꿀 필요 없음
1 7 2 8 // 4 9 3 5 // 6 -> 2 과 3 비교 바꿀 필요 없음
1 7 2 8 // 4 9 3 5 // 6 -> 8 과 5 비교 바꿈
1 7 2 5 // 4 9 3 8 // 6
>Step 2 ( k=2 )
1 7 // 2 5 // 4 9 // 3 8 // 6 -> 1 과 2 비교 바꿀 필요 없음
1 7 // 2 5 // 4 9 // 3 8 // 6 -> 2 과 4 비교 바꿀 필요 없음
1 7 // 2 5 // 4 9 // 3 8 // 6 -> 4 과 3 비교 바꿈1 7 // 2 5 // 3 9 // 4 8 // 6
1 7 // 2 5 // 3 9 // 4 8 // 6 -> 4 과 6 비교 바꿀 필요 없음
1 7 // 2 5 // 3 9 // 4 8 // 6 -> 7 과 5 비교 바꿈
1 5 // 2 7 // 3 9 // 4 8 // 6
1 5 // 2 7 // 3 9 // 4 8 // 6 -> 7 과 9 비교 바꿀 필요 없음
1 5 // 2 7 // 3 9 // 4 8 // 6 -> 9 과 8 비교 바꿈
1 5 // 2 7 // 3 8 // 4 9 // 6
>Step 3 ( k=1 ) !! 여기서 부터는 Insert Sort
1 5 2 7 3 8 4 9 6 -> 1 과 5 비교 바꿀 필요 없음
1 5 2 7 3 8 4 9 6 -> 5 과 2 비교 바꿈
1 2 5 7 3 8 4 9 6
1 2 5 7 3 8 4 9 6 -> 1 과 2 비교 바꿀 필요 없음
1 2 5 7 3 8 4 9 6 -> 5 과 7 비교 바꿀 필요 없음
1 2 5 7 3 8 4 9 6 -> 7 과 3 비교 바꿈
1 2 5 3 7 8 4 9 6
1 2 5 3 7 8 4 9 6 -> 5 과 3 비교 바꿈
1 2 3 5 7 8 4 9 6
1 2 3 5 7 8 4 9 6 -> 2 과 3 비교 바꿀 필요 없음
다음은 8 그 다음은 4 그 다음은 9 순으로 비교
참고 영상 링크
영상은 스타일이 좀 다릅니다
InsertSort
1 7 2 8 6 9 3 5 4
두번째 원소부터 시작
>step 1
↓
1 7 2 8 6 9 3 5 4 -> 1 과 7 비교 바꿀 필요 없음
>step 2
↓
1 7 2 8 6 9 3 5 4 -> 2 와 7 비교 바꿈
↓
1 2 7 8 6 9 3 5 4 -> 2 와 1 비교 바꿀 필요 없음
>step 3
↓
1 2 7 8 6 9 3 5 4 -> 8 과 7 비교 바꿀 필요 없음
>step 4
↓
1 2 7 8 6 9 3 5 4 -> 6 과 8 비교 바꿈
↓
1 2 7 6 8 9 3 5 4 -> 6 과 7 비교 바꿈
↓
1 2 6 7 8 9 3 5 4 -> 6 과 2 비교 바꿀 필요 없음
>step 5 는 9부터 시작
.... 이런 식으로
참고 영상 링크
피드 구독하기:
글 (Atom)